Reinforcement learning (RL) has applications in various fields, and one such important application can be found in aligning language models with human values. Reinforcement learning from Human Feedback (RLHF) emerges as a pivotal technology in this alignment field. One of the challenges pertains to the limitations of reward models that serve as proxies for human preferences in driving RL optimization. Incorrect and ambiguous preference pairs in the dataset pose obstacles to accurate human intent capture, and reward models trained on specific data distributions struggle to generalize outside that distribution, hindering iterative RLHF training.
The reward model is central to the RLHF process, acting as a primary mechanism to incorporate human preferences and feedback into the learning process. Functioning as a reward function, this model guides AI system optimization towards objectives aligned with human preferences. The evolution of RLHF traces back to integrating concepts like preferences, rewards, and costs that are crucial in probability theory and decision theory development. The RLHF pipeline typically includes supervised fine-tuning, preference sampling and reward model training, and RL fine-tuning using proximal policy optimization.
Researchers at Fudan NLP Lab, Fudan Vision and Learning Lab, and Hikvision Inc. have proposed novel RLHF methods. They have measured preference strength via a voting mechanism involving multiple reward models. The research introduces techniques to mitigate incorrect and ambiguous preferences in datasets. Contrastive learning enhances the ability of reward models to distinguish chosen from rejected responses, improving overall generalization. Meta-learning further facilitates iterative RLHF optimization, refining the reward model’s discernment of subtle differences in out-of-distribution samples.
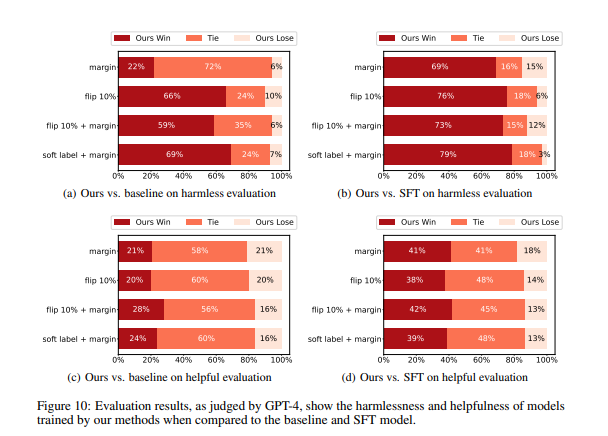
Experiments feature SwAV and SimCSE approaches on Llama 2 with 7 billion parameters. Diverse datasets validate proposed methods. The datasets employed include SFT (96k conversations from ShareGPT.com), Anthropic-RLHF-HH (170k comparisons for human preference data), Reddit TL;DR (123,169 posts with human-authored summaries for summarization), Oasst1 (for helpfulness prompts), and PKU-SafeRLHF (for harmlessness prompts), contributing to robust out-of-distribution generalization. The denoising methods demonstrate stable performance across all three validation sets, delivering better overall performance. The four proposed methods significantly improve when responding to harmful prompts, indicating the potential impact of noisy data in the preference data.
The exploration of RLHF in translation, with promising results, hints at potential avenues for future research in this dynamic field. Pursuing a more robust reward model, identified as an underexplored topic in language models, emerges as a crucial area for further investigation. The researchers emphasize the practicality of the study and the use of straightforward analytical methods and common algorithms, indicating a focus on gaining insights and understanding about alignment rather than innovation in methods.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.

: A New Learning-to-Reason Method for Multimodal Large Language Models")







 Language Model with 671B Total Parameters with 37B Activated for Each Token")