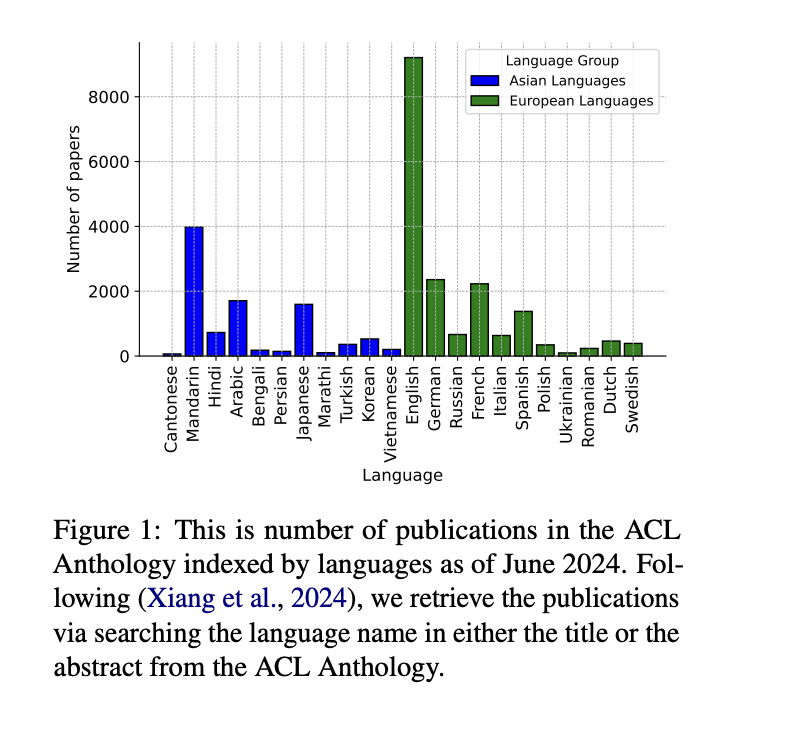
Large language models (LLMs) have revolutionized natural language processing (NLP), particularly for English and other data-rich languages. However, this rapid advancement has created a significant development gap for underrepresented languages, with Cantonese being a prime example. Despite being spoken by over 85 million people and holding economic importance in regions like the Guangdong-Hong Kong-Macau Greater Bay Area, Singapore, and North America, Cantonese remains severely underrepresented in NLP research. This disparity is especially concerning given the language’s widespread use and the economic significance of Cantonese-speaking regions. The lack of NLP resources for Cantonese, particularly when compared to languages from similarly developed areas, poses a critical challenge for researchers and practitioners aiming to develop effective language technologies for this widely spoken language.
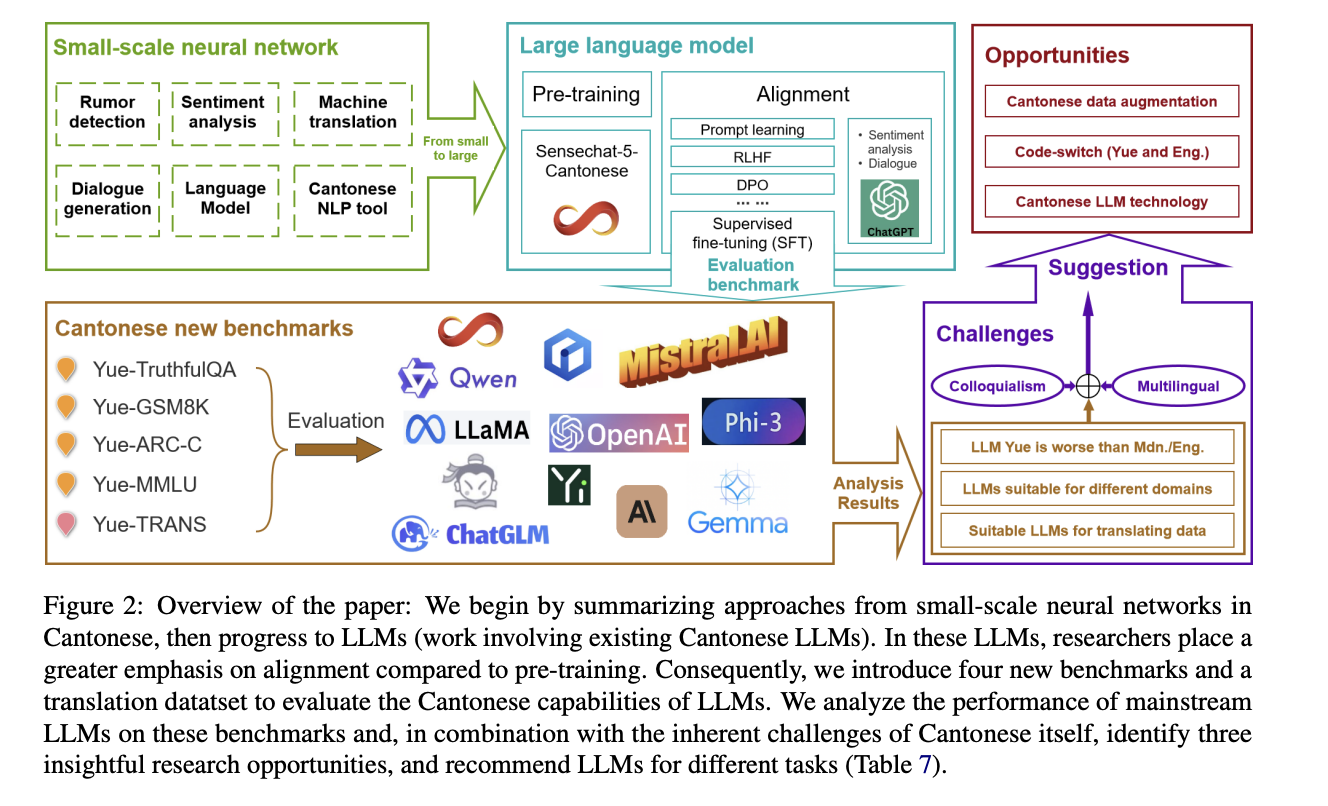
The development of Cantonese-specific LLMs faces significant challenges due to limited research and resources. Most existing Cantonese LLM technology remains closed-source, hindering widespread progress in the field. While some small-scale neural networks have been developed for specific Cantonese NLP tasks such as rumor detection, sentiment analysis, machine translation, dialogue systems, and language modeling, comprehensive LLM solutions are lacking. The scarcity of training data and benchmarks for Cantonese LLMs further complicates development efforts. Existing data resources and evaluation metrics are insufficient for comprehensively assessing the various capabilities of Cantonese LLMs. This lack of robust evaluation tools makes it difficult to measure progress and compare different models effectively, ultimately slowing down the advancement of Cantonese language technology in the rapidly evolving landscape of NLP and LLMs.

To mitigate the challenges in evaluating Cantonese language models, researchers from The Chinese University of Hong Kong and The University of Hong Kong have developed a comprehensive set of benchmarks specifically designed for Cantonese LLMs. These new evaluation tools include YueTruthful, Yue-GSM8K, Yue-ARC-C, Yue-MMLU, and Yue-TRANS, which assess various aspects of language model performance in Cantonese. These benchmarks focus on factual generation, mathematical logic, complex reasoning, general knowledge, and translation capabilities, respectively. Derived from existing English or Mandarin datasets, these Cantonese benchmarks have undergone meticulous translation and manual review to ensure accuracy and cultural relevance. Using these newly developed benchmarks, the researchers conducted an extensive analysis of twenty-three mainstream Cantonese and general-purpose LLMs, evaluating their proficiency in Cantonese language tasks. Additionally, the study explored which LLMs are most suitable for producing high-quality Cantonese translations, providing valuable insights for future development in Cantonese NLP.
Cantonese small-scale neural network
Cantonese NLP research encompasses various domains, including rumor detection, sentiment analysis, machine translation, and dialogue systems. For rumor detection, specialized models like XGA and CantoneseBERT have been developed, incorporating attention mechanisms and glyph-pronunciation features. Sentiment analysis has progressed from basic machine learning to advanced techniques using Hidden Markov Models and Transformers. Machine translation has evolved from rule-based systems to statistical and neural approaches, with recent focus on unsupervised methods and large-scale datasets. Dialogue summarization and generation have seen advancements with fine-tuned models like BertSum. Language modeling faces challenges due to data scarcity, while various NLP tools cater to specific Cantonese processing needs.
Cantonese large language model
Recent advances in Cantonese LLMs show promise despite resource scarcity and language-specific challenges. Alignment techniques like prompting, supervised fine-tuning, and reinforcement learning from human feedback have proven effective for adapting these models to downstream tasks while addressing biases and cultural nuances. Notable applications include ChatGPT’s success in Cantonese dialogue and sentiment analysis, as demonstrated in a Hong Kong web counseling study. The CanChat bot exemplifies practical implementation, offering emotional support to students during the COVID-19 pandemic. While both general-purpose and closed-source Cantonese LLMs demonstrate potential, quantifying their performance remains challenging. To address this, researchers have proposed four new benchmarks specifically designed to evaluate and advance the Cantonese capabilities of large language models.
The development of Cantonese language resources has a rich history, dating back to Matteo Ricci’s bilingual dictionary in the 16th century. Hong Kong institutions have been instrumental in creating Cantonese corpora, including legislative records, children’s dialogues, and media transcriptions. Recent efforts focus on bridging the data gap between Cantonese and major languages, with initiatives like parallel treebanks and comprehensive dictionaries. To address the lack of Cantonese-specific LLM evaluation tools, researchers have developed four new benchmarks: YueTruthfulQA for factual generation, Yue-GSM8K for mathematical logic, Yue-ARC-C for complex reasoning, and Yue-MMLU for general knowledge. These datasets, translated from English or Mandarin counterparts, underwent rigorous review by trilingual experts to ensure accuracy and cultural relevance.
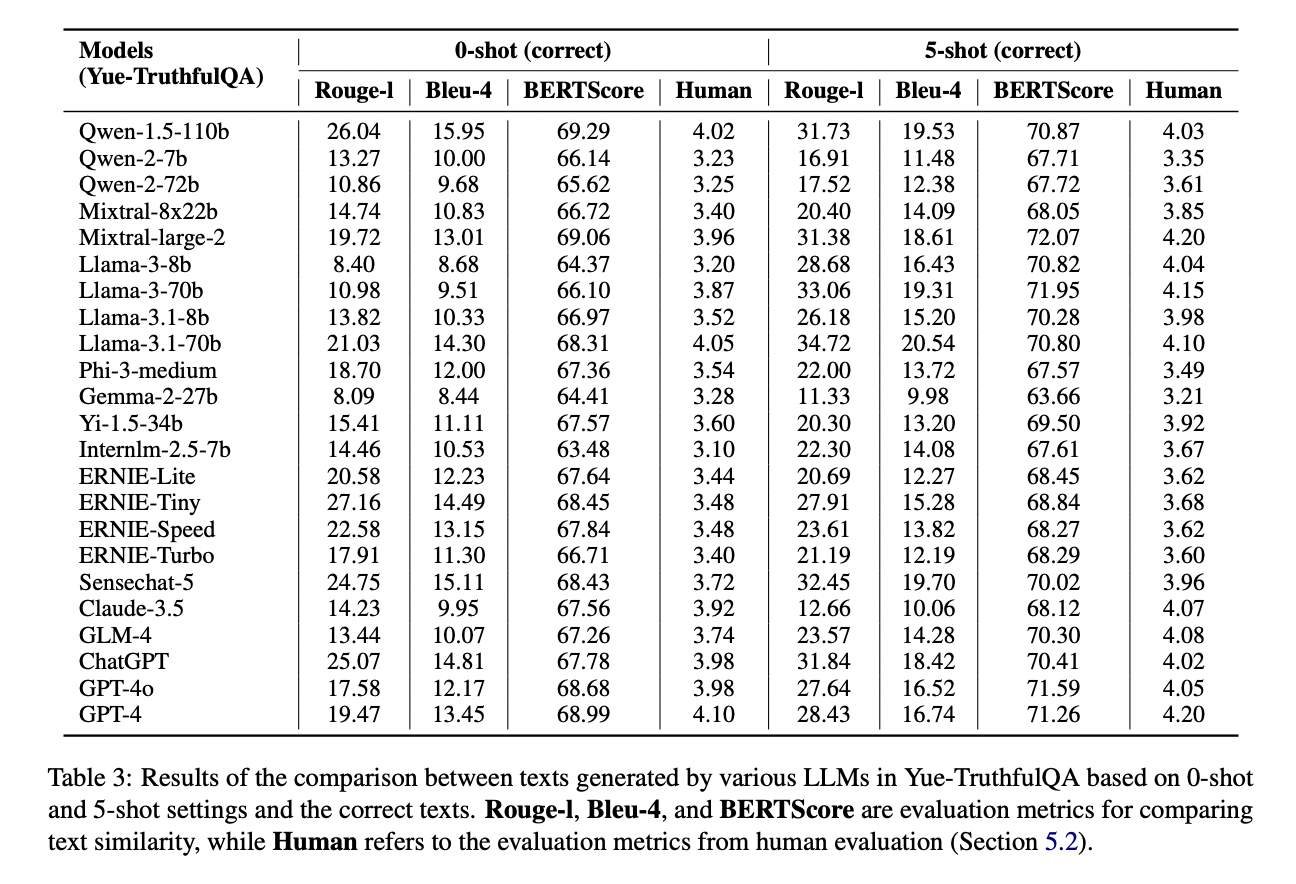
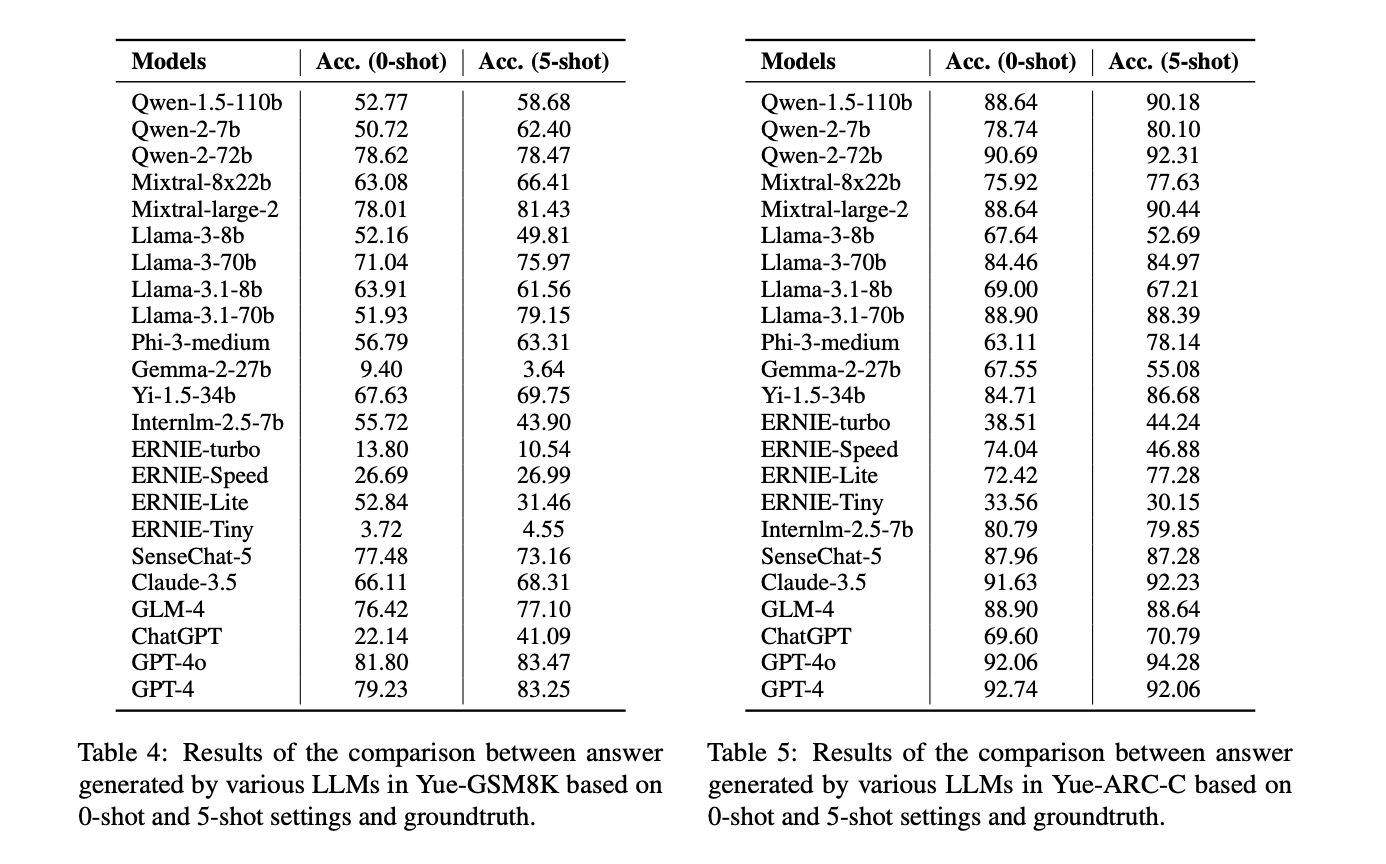
The performance of Cantonese LLMs lags behind their Mandarin and English counterparts. Rouge-l and Bleu-4 metrics excel in evaluating key information extraction, while BERTScore assesses deep semantic similarities. Generally, 5-shot settings outperform 0-shot, demonstrating the benefit of additional references. Mainstream LLMs consistently perform better in English than in Cantonese, highlighting the need for more Cantonese-focused development. Different model series show varying strengths across tasks. Qwen-1.5-110b and Mixtral-large-2 lead in factual generation, while GPT-4 and GPT-4o excel in mathematical logic. For complex reasoning, GPT-4 consistently tops performance charts, closely followed by Qwen and Mixtral models. Qwen-2-72b shows the best performance across various MMLU topics.
Cantonese NLP faces unique challenges due to its significant differences from Standard Chinese, particularly in colloquial usage. The abundance of unique expressions, slang, and cultural nuances in Cantonese complicates the adaptation of Standard Chinese-based models. Additionally, the multilingual nature of Cantonese communication, with frequent code-switching between Cantonese, Standard Chinese, and English, poses further challenges for NLP systems.
To address these challenges and advance Cantonese NLP, several opportunities emerge. Data augmentation techniques, including label-invariant and label-variant methods, can help overcome the scarcity of Cantonese-specific data. Leveraging high-capability closed-source models or cost-effective open-source alternatives for dataset translation and augmentation is recommended. Researchers should focus on developing models that can effectively handle code-switching and multilingual contexts. Based on benchmark performances, models from the Qwen, Mixtral, Llama, and Yi series are recommended for various Cantonese NLP tasks, with specific model selection depending on task requirements and available resources.
This study addresses the critical gap in Cantonese NLP research, highlighting the language’s underrepresentation despite its significant global speaker base and economic importance. The researchers from The Chinese University of Hong Kong and The University of Hong Kong developed robust benchmarks (YueTruthful, Yue-GSM8K, Yue-ARC-C, Yue-MMLU, and Yue-TRANS) to evaluate Cantonese LLMs. These tools assess factual generation, mathematical logic, complex reasoning, general knowledge, and translation capabilities. The study analyzed 23 mainstream LLMs, revealing that Cantonese models generally lag behind their English and Mandarin counterparts. Different models excelled in various tasks, with Qwen, Mixtral, and GPT series showing promising results. The research also identified key challenges in Cantonese NLP, including colloquialisms and code-switching, and proposed opportunities for advancement through data augmentation and specialized model development.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and LinkedIn. Join our Telegram Channel.
If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit
Asjad is an intern consultant at Marktechpost. He is persuing B.Tech in mechanical engineering at the Indian Institute of Technology, Kharagpur. Asjad is a Machine learning and deep learning enthusiast who is always researching the applications of machine learning in healthcare.

: A New Learning-to-Reason Method for Multimodal Large Language Models")







 Language Model with 671B Total Parameters with 37B Activated for Each Token")